Weakly Supervised Triplet Learning of Canonical Plane Transformation for Joint Object Recognition and Pose Estimation
[Abstract]
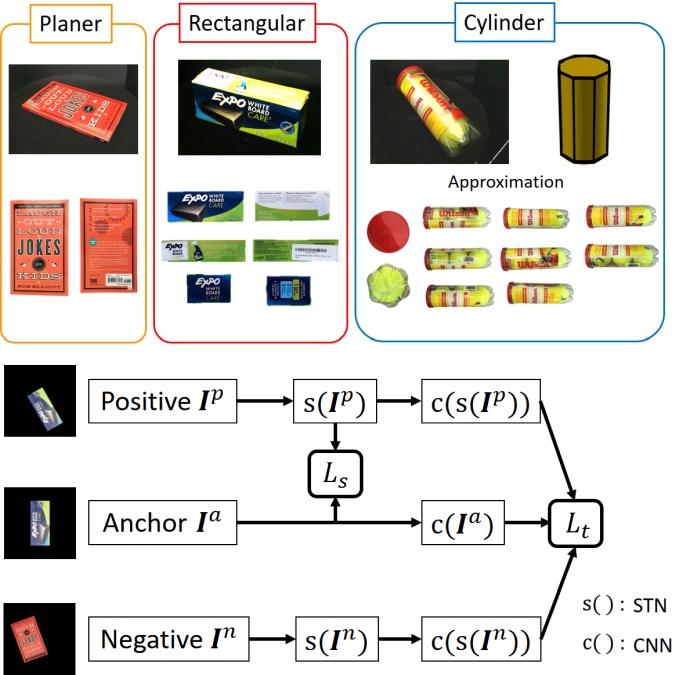
We propose a method for jointly performing object recognition and pose estimation using training samples of canonical planes to reduce the effort of data label supervision. Collecting a sufficient number of training samples is important to realizing high performance. However, labeling pose parameters is time consuming. We thus train our network model using only object class labels without explicitly labeling pose parameters. To recognize objects and estimate their poses, we design a network with a spatial transformer in a contrastive learning manner such that the canonical plane of an object is always transformed to a certain pose and the features are consistent with those of the object class. Experiments show that our method has improved accuracy in object recognition and lower error in pose estimation compared with simply using triplet learning or a spatial transformer network on a publicly available dataset.
[Publications]
- Kouki Ueno, Go Irie, Masashi Nishiyama, Yoshio Iwai,
Weakly Supervised Triplet Learning of Canonical Plane Transformation for Joint Object Recognition and Pose Estimation,
Proceedings of IEEE International Conference on Image Processing (ICIP), pp. 2476 - 2480, September 2019.- 上野 高貴, 西山 正志, 岩井 儀雄,
物体検出のための側面を用いた訓練サンプル生成による撮影枚数の削減,
精密工学会誌, vol. 84, no. 12, pp.1041 - 1049, December 2018.