Joint Object Recognition and Pose Estimation using Multiple-anchor Triplet Learning of Canonical Plane
[Abstract]
Accurate object recognition and pose estimation models are essential for practical applications of robot arms, such as picking products on a shelf.
Training such a model often requires a large-scale dataset with qualified labels for both object classes and pose parameters, and collecting accurate pose labels is particularly costly.
Our recent paper proposed a triplet learning framework for joint object recognition and pose estimation without explicit pose labels by learning a spatial transformer network to estimate the pose difference of an input image from an anchor image depicting the same object in a reference pose.
However, our analysis suggests that the pose estimation accuracy is severely degraded for input images with large pose differences.
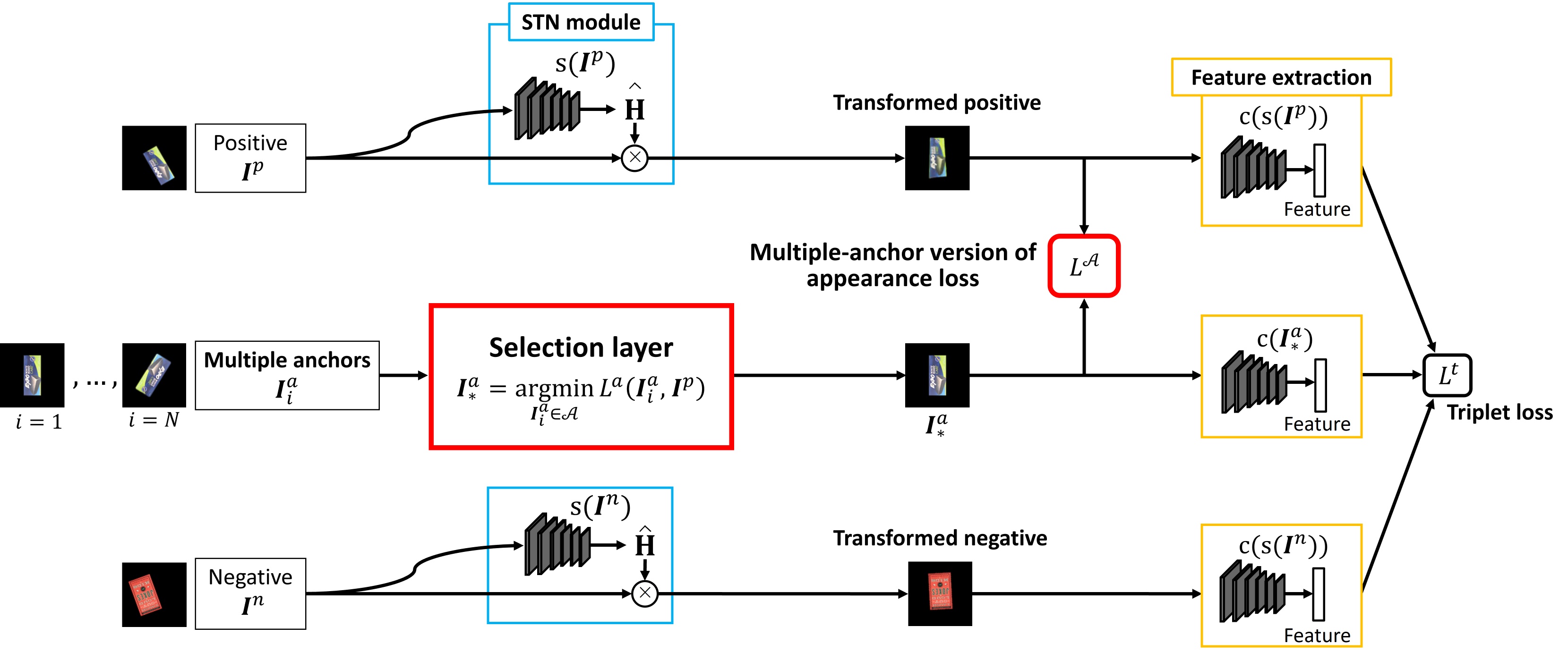
To address this problem, we propose a new learning approach called multiple-anchor triplet learning.
The basic idea is to give dense reference poses by preparing multiple anchors so that there is at least one anchor image having a small pose difference to the input image.
Our multiple-anchor triplet learning is an extension of the standard single-anchor triplet learning to the multiple-anchor case.
Inspired by the idea of multiple instance learning, we introduce a selection layer that automatically chooses the best anchor for each input image and allows the network to be trained end-to-end to minimize triplet-based losses.
Experiments with three benchmark datasets in product picking scenarios demonstrate that our method significantly outperforms existing methods in both object recognition and pose estimation accuracy.
[Publications]
