Pedestrian Age Recognition using Contrastive Learning by Automatically Generating Descriptions with High Inter-class Separability
[Abstract]
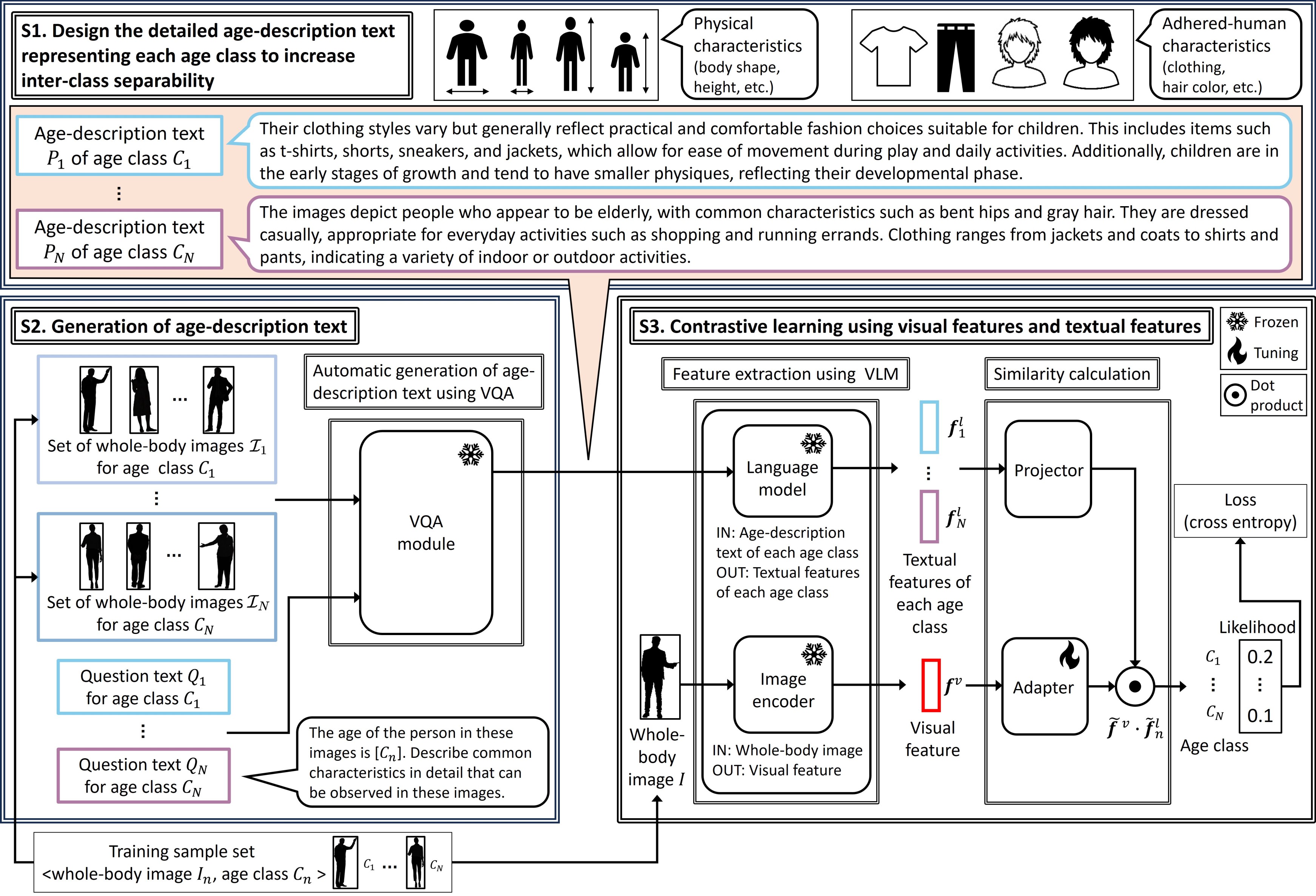
There is a need to accurately recognize pedestrian age classes from whole-body images with minimal manual effort. Recent studies have improved age recognition accuracy by exploiting vision--language models (VLMs). However, the age-description texts provided to the VLM are not designed to be sufficiently discriminative across age classes. Moreover, preparing these texts entails considerable manual work. We address these issues by automatically generating detailed, class-specific age-description texts that are highly separable among age classes and using them in a contrastive learning framework. Our method expands the vocabulary of physical and adhered-human characteristics that represent each age class, thereby sharpening inter-class separability. Leveraging a VLM-powered visual question answering (VQA) module, our approach produces detailed age-description texts from concise question texts without the need for trial and error. The age-description texts yield strongly discriminative textual features, which also align discriminative visual features by contrastive learning. Experimental results on public datasets (RAPv2.0, PETA, MSP60k, and PA100k) demonstrated that our method achieves an average age recognition accuracy of 84.1\%, outperforming the best baseline by 4.6 percentage points. We also confirmed that our method eliminates the trial and error of manually crafting age-description texts.
[Publications]
- Takumi Ozaki, Hidenori Kuribayashi, Michiko Inoue, Masashi Nishiyama,
Pedestrian Age Recognition using Contrastive Learning by Automatically Generating Descriptions with High Inter-class Separability,
IEEE Access, vol. 13, pp. 146492 - 146502, August 2025. [DOI]- 尾崎 匠, 西山 正志,
年齢認識および性別認識における手法・データセット・クラス不均衡に起因する精度変化の要因調査,
信学技報, vol. 125, no. 424, PRMU2025-60, pp. 102 - 107, March 2026. [Slides]- 尾崎 匠, 栗林 英範, 井上 路子, 西山 正志,
クラス間で良く分離された説明文を自動生成する大規模視覚言語モデルを用いた対照学習による歩行者年齢層認識,
信学技報, vol. 124, no. 445, PRMU2024-54, pp. 47 - 52, March 2025. [Slides] [Short movie]